Machine Learning Interviews: Top ML Algorithm Questions You Need to Know

Machine learning (ML) interviews can be quite stressful. It does not matter whether you are looking for a position in the Data Science team of major tech companies such as Google, Apple, Amazon or start-up companies, you should always be ready for questions on ML algorithms. Knowing the difference between how common algorithms are used in practice and their definitions can be a life-saver during the tense moments before and during the interview.
In this blog, we will examine some of the most frequently asked interview questions about machine learning algorithms, especially the ones from Meta, Amazon, and Netflix. We will divide these questions into several sections, one of them is algorithm type, and give you some recommendations on how to approach these questions, what to emphasis on, and some techniques intended for your forthcoming interview.
1. Random Forest: The Champion of ML Interviews
Random Forest algorithms are among the most common topics in ML interviews because they are versatile, easy to understand, and frequently used in classification and regression tasks. A Random Forest builds multiple decision trees during training and outputs the mode of the classes for classification or the mean prediction for regression.

Common Interview Questions:
- How does Random Forest handle overfitting?
- What are the advantages and disadvantages of using Random Forest compared to other algorithms?
- Explain feature importance in a Random Forest model.
Pro Tip: Interviewers often ask about the bias-variance tradeoff and how Random Forest reduces both. Highlight its power in reducing overfitting by using an ensemble of decision trees and explain how this improves overall accuracy without relying on a single model.
2. Logistic Regression: A Simple Yet Powerful Classifier
Logistic regression may be simple, but it’s a staple in many interview questions due to its foundational nature in binary classification. You’ll frequently be asked to explain its workings, assumptions, and applications in various industries.

Common Interview Questions:
- What is the difference between Logistic Regression and Linear Regression?
- Explain the role of the sigmoid function in Logistic Regression.
- How do you handle imbalanced datasets with Logistic Regression?
Pro Tip: Discuss how logistic regression applies to real-world problems, such as spam detection or customer churn. Additionally, be prepared to discuss techniques like regularization (L1, L2) and how to deal with high-dimensional data in logistic regression models.
3. Gradient Boosting: Mastering Ensemble Techniques
Gradient Boosting Machines (GBMs) are powerful techniques used in predictive modeling. Since boosting focuses on correcting the mistakes of the prior models, expect to be asked about how boosting differs from bagging (used in Random Forest) and why it’s effective in reducing both bias and variance.

Common Interview Questions:
- Explain the working of Gradient Boosting.
- What is the difference between AdaBoost and Gradient Boosting?
- How does Gradient Boosting handle overfitting?
Pro Tip: Dive deep into the learning rate, shrinkage, and number of trees in Gradient Boosting. Most interviewers want to know how you would tweak hyperparameters and deal with issues like overfitting or high computational costs.
4. Linear Regression: The Core of Regression Analysis
Linear regression, despite its simplicity, is a foundational topic in ML interviews, especially for roles focusing on predictive modeling. It’s often one of the first algorithms candidates are asked to explain, particularly regarding assumptions, limitations, and use cases.
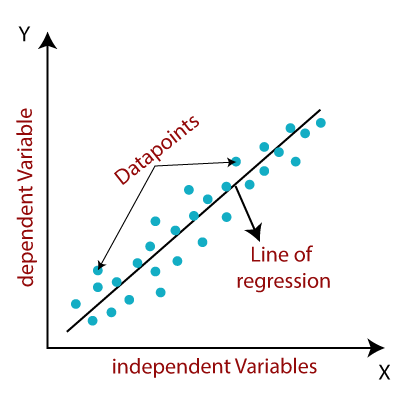
Common Interview Questions:
- What are the key assumptions of Linear Regression?
- How do you evaluate the performance of a Linear Regression model?
- Explain multicollinearity and how to detect it.
Pro Tip: You should be able to explain the key metrics like R-squared, adjusted R-squared, Mean Squared Error (MSE), and Root Mean Squared Error (RMSE). Discuss how these metrics are useful in evaluating model performance and suggest ways to improve predictions, such as feature engineering or regularization techniques.
5. Decision Tree: Interpretable Yet Prone to Overfitting
Decision trees are highly interpretable and useful for a wide variety of tasks. However, interviewers will often ask how you would deal with its propensity to overfit, particularly in situations where the dataset is noisy or complex.

Common Interview Questions:
- How does a Decision Tree make splits?
- What are some methods to avoid overfitting in Decision Trees?
- Explain the concept of Gini Impurity and Information Gain.
Pro Tip: Bring up how pruning and setting a minimum number of samples per leaf can help combat overfitting. Also, show an understanding of the computational complexity involved in growing and pruning decision trees.
6. K-Means Clustering: The Go-To for Unsupervised Learning
K-Means is one of the most frequently used algorithms in unsupervised learning, and interviewers will focus on its clustering performance, especially how you handle initialization and determine the optimal number of clusters (K).

Common Interview Questions:
- How do you choose the value of K in K-Means Clustering?
- Explain the “elbow method” and how it’s used in K-Means.
- What is the limitation of K-Means?
Pro Tip: Demonstrate knowledge of the elbow method or silhouette analysis for choosing K. If asked about K-Means limitations, bring up how it assumes spherical clusters and struggles with non-linearly separable data.
7. Neural Networks: The Power Behind Deep Learning
Neural Networks and Deep Learning have gained immense popularity with advancements in computational power and data availability. You might not get extremely technical questions, but expect to be asked about the fundamentals and trade-offs.
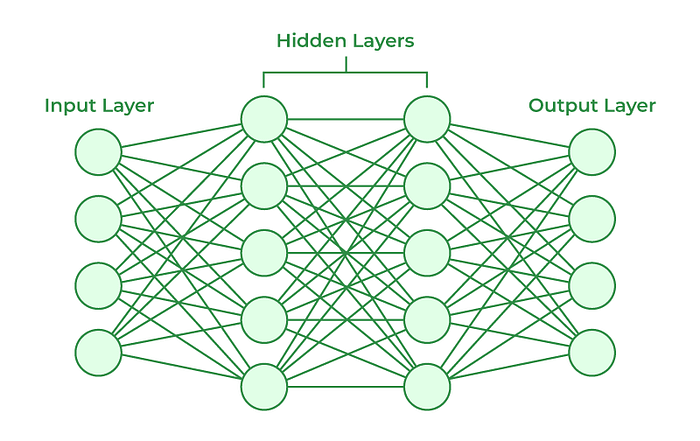
Common Interview Questions:
- Explain backpropagation in Neural Networks.
- What is the vanishing gradient problem, and how do you mitigate it?
- How do Neural Networks differ from traditional machine learning models?
Pro Tip: Brush up on how Neural Networks handle complex, non-linear relationships in data. Emphasize practical applications like image classification and natural language processing. If possible, share personal projects involving deep learning to add credibility to your knowledge.
8. Support Vector Machine (SVM): Maximize the Margin
Though SVMs aren’t as widely used as Neural Networks or Tree-based models today, they remain a frequent topic in interviews due to their mathematical foundation and strong theoretical backing.
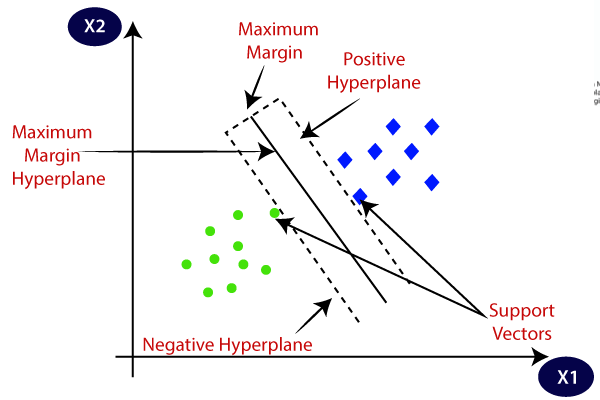
Common Interview Questions:
- What is the kernel trick in SVMs?
- Explain how SVMs work for classification.
- What is the difference between a hard margin and a soft margin in SVM?
Pro Tip: Be prepared to explain kernel functions (linear, polynomial, RBF) and how they transform data into higher dimensions. If asked about computational cost, mention that SVMs scale poorly with large datasets, which is why they aren’t as popular today.
9. Naive Bayes: Fast and Simple
Naive Bayes is one of the simplest yet most efficient classifiers, particularly for tasks like text classification. Expect questions about how it handles independence assumptions and how this impacts its performance.

Common Interview Questions:
- What is the Naive Bayes assumption?
- How does Naive Bayes work in text classification?
- What are the limitations of Naive Bayes?
Pro Tip: Point out how Naive Bayes works well in high-dimensional problems like text classification, even when the independence assumption is violated. Be ready to discuss its limitations, particularly when features are correlated.
